成功案例

案例一:某品牌微信公众号运营
通过精准的内容策划和推广,粉丝量增长了 50%,文章阅读量大幅提升。

案例二:某企业微信小程序开发
定制化小程序上线后,用户活跃度提高了 30%,业务转化率显著提升。
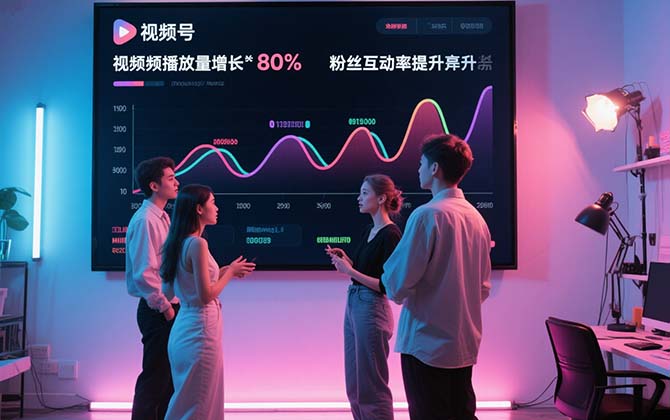
案例三:某网红微信视频号内容生产
为网红打造个性化视频内容,视频播放量平均增长 80%,粉丝互动率大幅提高。

案例四:某电商新媒体整合营销
通过公众号、小程序和视频号的整合营销,电商销售额增长了 60%。
