
在node.js和puppeteer的帮助下,我正在将一个网页转换成一个。pdf文件。
这工作很好,但我想删除所有的链接在这一页之前,转换成。pdf文件,因为否则。pdf文件包括这些链接,不能打开在我的应用程序时,有人点击他们。 有没有办法这样做?
该页是一个使用JavaScript的。aspx页。 链接都以“javascript:__”开头。 这是一个显示我们的餐点的内联网页面,我只想把mealplan显示为。pdf。
我的。js文件中的内容如下所示:
const puppeteer = require('puppeteer');
let url = 'http://my-url.de/meals.aspx'
let browser = await puppeteer.launch()
let page = await browser.newPage()
await page.goto(url, {waitUntil: 'networkidle2' })
await page.pdf({
format:"A4",
path:files[0],
displayHeaderFooter: false,
printBackground:true
})
在我的应用程序它说“网址不能打开”,这就是为什么我希望这些链接被删除。
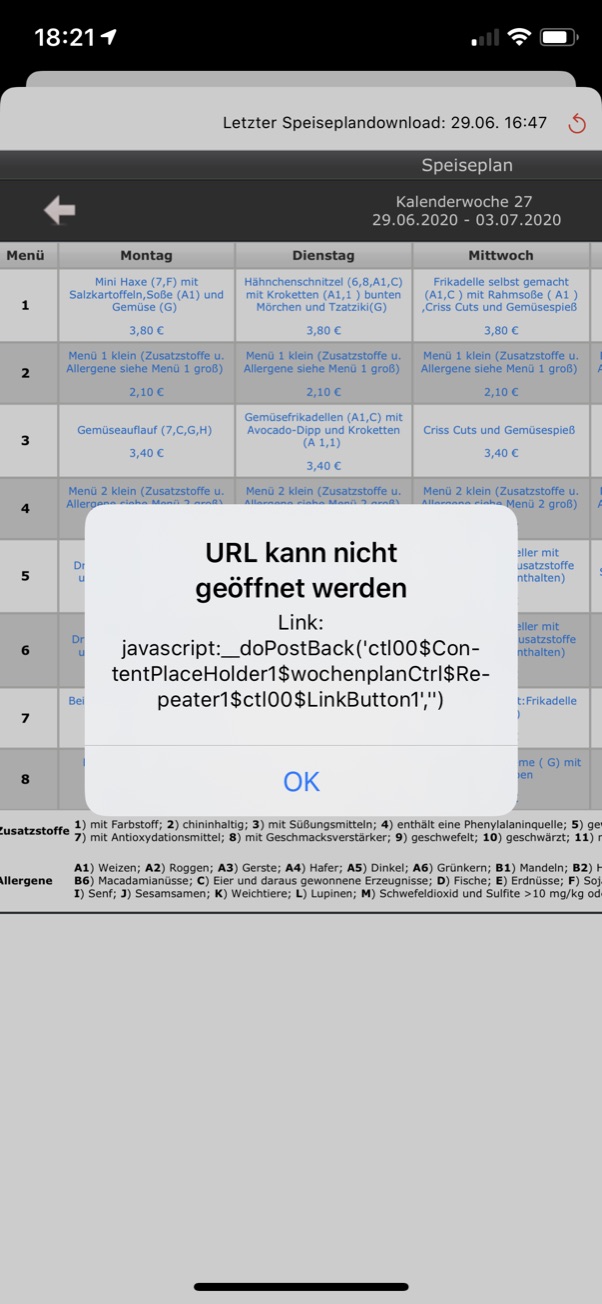
看起来这些不是正确的链接,至少它们不是带有href指向网站的标签。
相反,您处理的是需要javascript导航的链接,这就是为什么这些链接在PDF中不起作用的原因。
您可以做的是在捕获页面之前将所有这些无效的href转换为对pdf有效的内容。
查看下面我的尝试。 它可能你需要修改它一点适合你的情况,因为我没有访问实际的网站,你试图解析。
const puppeteer = require('puppeteer');
let url = 'http://my-url.de/meals.aspx'
(async() => {
let browser = await puppeteer.launch()
let page = await browser.newPage()
await page.goto(url, {
waitUntil: 'networkidle2'
})
// Modifing the page here
await page.evaluate(_ => {
// Capture all links that start with javascript on the href property
// and change it to # instead.
document.querySelectorAll('a[href^="javascript"]')
.forEach(a => {
a.href = '#'
})
});
await page.pdf({
format: "A4",
path: files[0],
displayHeaderFooter: false,
printBackground: true
})
})()
