
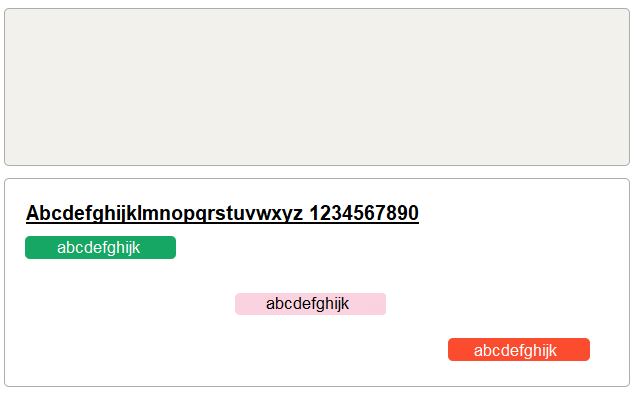
我想获得第二个矩形顶部的黑色粗体文本的(x,y)坐标,以及三个彩色矩形的(x,y)坐标。
我已经准备好了面具,除了黑色文字的面具,我不知道。 但是,文本总是在矩形的顶部,所以如果我能够计算出底部大矩形的位置,我也会得到文本的位置。

我尝试使用ConnectedComponents函数基于这个注释,但是除了对不同的对象进行着色和分组之外,我没有继续前进,所以我没有在下面包含这段代码以使事情尽可能清楚。
下面是我到目前为止的代码:
import cv2
import numpy as np
import imutils
PATH = "stackoverflow.png"
img = cv2.imread(PATH)
imgHSV = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
mask_border = cv2.inRange(imgHSV,np.array([0,0,170]),np.array([0,0,175]))
mask_green = cv2.inRange(imgHSV,np.array([76,221,167]),np.array([76,221,167]))
mask_pink = cv2.inRange(imgHSV,np.array([168,41,245]),np.array([172,41,252]))
mask_red = cv2.inRange(imgHSV,np.array([4,207,251]),np.array([4,207,251]))
#mask_black = ???
all_masks = cv2.bitwise_or(mask_border, mask_green)
all_masks = cv2.bitwise_or(all_masks, mask_pink)
all_masks = cv2.bitwise_or(all_masks, mask_red)
cv2.imshow("Masks", all_masks)
imgResult = cv2.bitwise_and(img,img,mask=all_masks)
cv2.imshow("Output", imgResult)
cv2.waitKey(0)
试一下这个例子:简单的blob检测器。 我会在你的实际蒙版上运行它,而不是rgb图像,因为它会在像你的蒙版这样的二值化图像上工作得相当好。 然后从返回的关键点中提取pt和size属性,就会得到斑点的中心和半径。 (tbh不确定它是平均半径还是最大半径而不进行测试)。 我可能甚至不会在您的用例中使用半径,从每个blob的中心点开始,我会在-x和-y轴(分别)中迭代搜索,从那个点开始。 在每一步,我会检查它是黑色还是白色像素,我会等到我看到一些可调节的可变数量的黑色像素在一排(基本上是为了避免触发在文本,但尝试触发在退出框和进入背景)。 这些x和y的坐标将是你的盒子的左上角。 如果你想,你可以做它在正的x和y方向也为了得到完整的包围盒。
SimpleBlobDetector
关键点
