
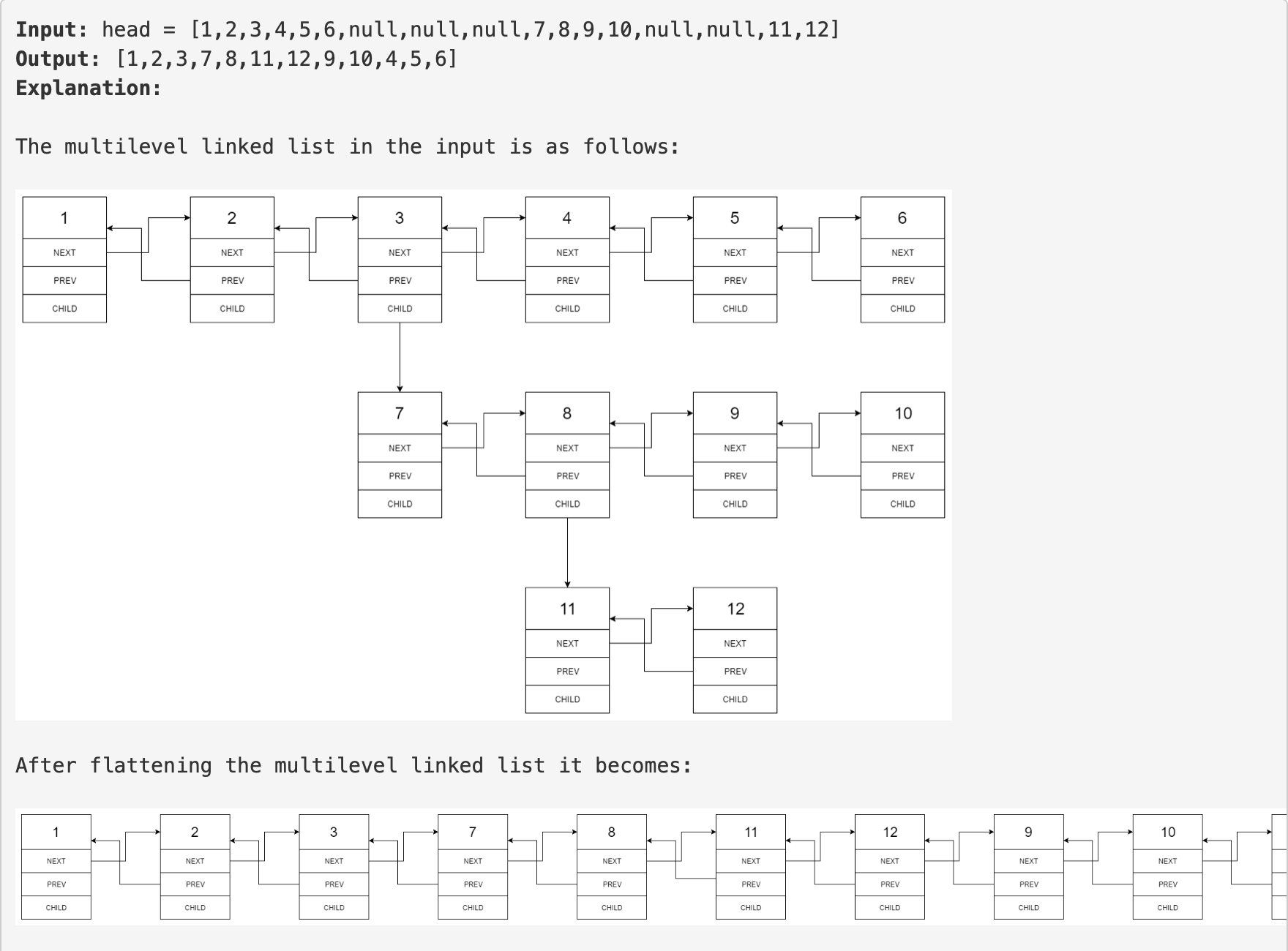
您将获得一个双向链表,除了下一个和前一个指针之外,它还可以有一个子指针,该子指针可能指向也可能不指向单独的双向链表。这些子列表可能有一个或多个自己的子列表,依此类推,以生成多级数据结构,如下面的示例所示。
class Solution {
/*Global variable pre to track the last node we visited */
Node pre = null;
public Node flatten(Node head) {
if (head == null) {
return null;
}
/*Connect last visted node with current node */
if (pre != null) {
pre.next = head;
head.prev = pre;
}
pre = head;
/*Store head.next in a next pointer in case recursive call to flatten head.child overrides head.next*/
Node next = head.next;
flatten(head.child);
head.child = null;
flatten(next);
return head;
}
}
对于这个问题,上面的leetcode解决方案有效。但我不明白这一点:
/*Store head.next in a next pointer in case recursive call to flatten head.child overrides head.next*/
Node next = head.next;
有人能解释一下这部分吗?head. child如何覆盖head.next?
flatten(head. child)可能会更改head.next,因为我们将上次访问的节点与当前节点连接的部分:
if (pre != null) {
pre.next = head;
head.prev = pre;
}
在这个阶段,pre代表旧的head,head代表head. child。所以我们实际上将我们的head与其child连接起来。但是如果我们这样做,我们将失去与实际的head.next的连接,因此我们必须将其保存在一个名为next的额外变量中。这就是为什么我们在调用flatten()函数之前保留它。
