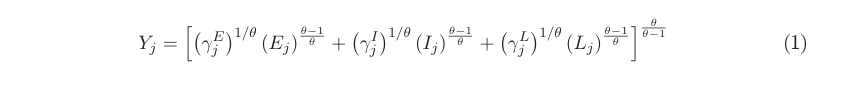我正在使用org. apache.pdfbox.text.PDFTextStripper版本2.0.26。它适用于大多数PDF。但它无法从线性化PDF中正确提取文本:提取的文本
有没有办法通过pdfbox或使用其他工具从线性化PDF中提取文本?
这是一个线性化的PDF示例
PDF示例的问题不在于它是线性化的。
实际问题是PDF中的大多数字体缺少文本提取所需的信息:它们既没有ToUnicode映射也没有有用的编码,而且它们是类型3字体,这阻止了从相关字体程序或CIDFont字典中检索附加信息。
特别是,此类PDF通常是显式生成的,以防止常规文本提取器提取文本。
对于这样的PDF基本上你唯一的选择是尝试OCR。
线性化不应该是文本提取的问题,但并非所有纯文本都如您所料,因为有些结构不能用纯文本描述。因此,不清楚您在源文件中显示的哪一部分,但简单的PDFtotext似乎没有问题。我会避免通用OCR可能会增加错误。数学公式最好由专用的方程转换器转换,它们OCR图像片段。https://mathpix.com/Snip是商业市场的领导者,很少有竞争对手看到https://www.sciaccess.net/en/InftyReader/

在这里,我们可以从pdf中看到infty孤立的svg公式及其OCR提取的字符Yj=γEj 1/θ(Ej)θ−1……这对于这种类型的反转是没有意义的。数学表格或公式的副本作为图像通常是最好的解决方案,否则结果很可能被破坏。注意如何识别一些大括号,但不是一些关键的大括号。