
我一直在尝试制作一个简单的函数,使用beautiful soup从一个名为Tangorin的网站上提取所有的例句,给出一本日语书。 我试着写了两种不同类型的函数来提取这些数据,但我就是不能让它工作。抱歉,这是一个很长的问题,但我试过一些东西,但没有工作,我只做了3个星期的编码。 我尝试拉取的数据结构如下所示:
下面是作为搜索词的单词页面上的一个句子的数据结构,网页https://tangorin.com/sentences?search=。
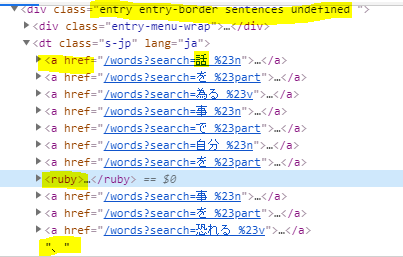
我试着把这一页上所有的句子都拉到一个单独的句子列表中。 每一个句子都在下面这样的一个区块里,我已经突出了我试图寻找的关键信息。
**<div class="entry entry-border sentences undefined ">**
<div class="entry-menu-wrap">
<button class="entry-menu-btn btn">
<svg class="icon" role="img" alt="" width="1em" height="1em" viewBox="0 0 50 50">
<use xlink:href="#icon-chevron-down">
</use>
</svg>
</button>
</div>
<dt class="s-jp" lang="ja">
<a href="/words?search=話 %23n">
<ruby>
**話**
<rt class="roma">hanashi</rt>
</ruby>
</a>
<a href="/words?search=を %23part">
<ruby>
**を**
<rt class="roma">wo</rt>
</ruby>
</a>
<a href="/words?search=為る %23v">
<ruby>
**する**
<rt class="roma">suru</rt>
</ruby>
</a>
<a href="/words?search=事 %23n">
<ruby>
**こと**
<rt class="roma">koto</rt>
</ruby>
</a>
<a href="/words?search=で %23part">
<ruby>
**で**
<rt class="roma">de</rt>
</ruby>
</a>
<a href="/words?search=自分 %23n">
<ruby>
**自分**
<rt class="roma">jibun</rt>
</ruby>
</a>
<a href="/words?search=を %23part">
<ruby>
**を**
<rt class="roma">wo</rt>
</ruby>
</a>
<ruby>
**曝け出す**
<rt class="roma">曝kedasu</rt>
</ruby>
<a href="/words?search=事 %23n">
<ruby>
**こと**
<rt class="roma">koto</rt>
</ruby>
</a>
<a href="/words?search=を %23part">
<ruby>
**を**
<rt class="roma">wo</rt>
</ruby>
</a>
<a href="/words?search=恐れる %23v">
<ruby>
**恐れず**
<rt class="roma">osorezu</rt>
</ruby>
</a>
**、**
<a href="/words?search=英語 %23n">
<mark>
<ruby>
**英語**
<rt class="roma">eigo</rt>
</ruby>
</mark>
</a>
<a href="/words?search=で %23part">
<ruby>
**で**
<rt class="roma">de</rt>
</ruby>
</a>
<a href="/words?search=他人 %23n">
<ruby>
**他人**
<rt class="roma">tanin</rt>
</ruby>
</a>
<a href="/words?search=と %23part">
<ruby>
**と**
<rt class="roma">to</rt>
</ruby>
</a>
<a href="/words?search=喋る %23v">
<ruby>
**しゃべる**
<rt class="roma">shaberu</rt>
</ruby>
</a>
<a href="/words?search=有らゆる %23pn-adj">
<ruby>
**あらゆる**
<rt class="roma">arayuru</rt>
</ruby>
</a>
<a href="/words?search=機会 %23n">
<ruby>
**機会**
<rt class="roma">kikai</rt>
</ruby>
</a>
<a href="/words?search=を %23part">
<ruby>
**を**
<rt class="roma">wo</rt>
</ruby>
</a>
<a href="/words?search=捕らえる %23v">
<ruby>
**とらえ**
<rt class="roma">torae</rt>
</ruby>
</a>
<a href="/words?search=なさる %23v">
<ruby>
**なさい**
<rt class="roma">nasai</rt>
</ruby>
</a>
**。**
<a href="/words?search=そうすれば %23adv">
<ruby>
**そうすれば**
<rt class="roma">sousureba</rt>
</ruby>
</a>
<a href="/words?search=直に %23n">
<ruby>
**じきに**
<rt class="roma">jikini</rt>
</ruby>
</a>
<a href="/words?search=形式張る %23n">
<ruby>
**形式張らない**
<rt class="roma">keishikiharanai</rt>
</ruby>
</a>
<a href="/words?search=会話 %23n">
<ruby>
**会話**
<rt class="roma">kaiwa</rt>
</ruby>
</a>
<a href="/words?search=の %23part">
<ruby>
**の**
<rt class="roma">no</rt>
</ruby>
</a>
<a href="/words?search=場面 %23n">
<ruby>
**場面**
<rt class="roma">bamen</rt>
</ruby>
</a>
<a href="/words?search=で %23part">
<ruby>
**で**
<rt class="roma">de</rt>
</ruby>
</a>
<a href="/words?search=気楽 %23n">
<ruby>
**気楽**
<rt class="roma">kiraku</rt>
</ruby>
</a>
<a href="/words?search=に %23part">
<ruby>
**に**
<rt class="roma">ni</rt>
</ruby>
</a>
<a href="/words?search=慣れる %23v">
<ruby>
**なれる**
<rt class="roma">nareru</rt>
</ruby>
</a>
<a href="/words?search=である %23aux-v">
<ruby>
**であろう**
<rt class="roma">dearou</rt>
</ruby>
</a>
**。**
</dt>
在类内部的问题是,我想要的数据以三种方式之一存储,在一个a=href超链接中,然后是一个ruby缩写。 或者在不在a=href内的ruby缩写中,或者有时在纯文本行中,如“,”,“。”,“?” 等等。
所以我在朋友使用beautiful Soup的大量帮助下编写了下面的代码:
# all of your sentences from anki deck
# also new sentences will go here
ALL_SENTENCES = set()
# This piece of code returns true if char is in the set of all roman letters
# and false if not
def is_english(char):
lower_case = ord("a") <= ord(char) <= ord("z")
upper_case = ord("A") <= ord(char) <= ord("Z")
return lower_case or upper_case
# This piece of code is to take a random Japanese word from a file and
# generate a Tangorin URL to the page of example
# sentencese for that word
def make_url(word):
return f"https://tangorin.com/sentences?search={word}"
# This function searches through all of the descendants that have been added into the total
def filter_jap(sentences):
jap_only = [
[word for word in sentence if not is_english(word[0])] for sentence in sentences
]
for sentence in jap_only:
as_string = "".join(sentence) + "\n"
print(as_string)
def get_random_sentence(all_sentences):
return random.choice(all_sentences)
def get_example_sentences(word):
url = make_url(word)
source = requests.get(url).text
soup = BeautifulSoup(source, "lxml")
all_sentences = []
curr_sentence = ""
for sentence in soup.findAll(
"div", class_="entry entry-border sentences undefined"
):
character_blocks = sentence.dt
for desc in character_blocks.descendants:
# end of sentence detected, add curr sentence to all sentence list
# and reset curr sentence
if desc == "。":
all_sentences.append(curr_sentence)
curr_sentence = ""
# if character is non-english (japanese) add it to current sentence
elif type(desc) == NavigableString and not is_english(desc[0]):
curr_sentence += desc
return all_sentences
def gen_example_sentence(word):
all_sentences = get_example_sentences(word)
random_choice = get_random_sentence(all_sentences)
return(random_choice)
with open('Japanese Words.txt', 'r', encoding="utf-8") as f:
for line in f:
x = gen_example_sentence(line)
print(x)`
这段代码的问题是当它遇到这样的块时:
<ruby>
**曝け出す**
<rt class="roma">曝kedasu</rt>
</ruby>
在这里,ruby缩写的rt类中的项在开头使用日语字符进行了错误的格式化,因此解析以英语字符开头的navigablestring类型的后代的for循环理解在这里完全失败。 所以我尝试用一种不同的方法来处理字符串,但是我的编码技巧仍然不够好,所以这是一个严重的失败:
`def make_url(word):
return f"https://tangorin.com/sentences?search={word}"
word = "英語"
url = make_url(word)
source = requests.get(url).text
soup = BeautifulSoup(source, "lxml")
all_sentences = []
curr_sentence = ""
for sentence in soup.findAll("div", class_="entry entry-border sentences undefined"):
y = sentence.dt
for line in y:
if str(type(line)) == "<class 'bs4.element.Tag'>":
x = str(line.ruby)
block = str(x.split('<'))
block = str(block.split('>'))
print(block)[3]
#else:
#curr_sentence += line
#print(curr_sentence)
#curr_sentence = ""`
我不知道如何着手解决这个问题,以提取出我所需的准确信息,从而成功地重新编译句子,然后将它们添加到一组字符串中。
对于一些额外的基于日语的知识,日语句子中的字符之间没有空格,除了一些像‘,’,‘,’,‘,’,‘,’,‘,’,‘,’,‘,’,‘,’,‘,’,‘,’,‘,’,‘,’,‘
另外,ruby标记是一种称为ruby缩写的东西,它是一种描述日语字符位置的方式,以及在上面使用英语字符阅读它的方式。 Roma“代表romaji,意思是日语单词的英文读数
抱歉,这是一个很长的问题,但我已经看了大量的youtube视频,关于beautifulsoup和其他解析方法,我只是不明白这个问题
另外,如果粗体不起作用,在xml块内,****指示器中的东西就是我想要取出的位。 本质上,我想要的是ruby缩写中的东西,而不是rt类中的东西,我还想要那些纯文本项“,”,“。”等。如果你运行原始的后代代码,你会得到99%准确的句子,看看我想要的输出是什么样的。 提前感谢任何帮忙的人!!!
您可以先提取带有英文单词的标记,然后使用.get_text()。
例如(希望输出正确,我看不懂日语):
import requests
from bs4 import BeautifulSoup
url = 'https://tangorin.com/sentences?search=%E8%8B%B1%E8%AA%9E'
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
for s in soup.select('.sentences'):
soup.select_one('.s-en').extract()
for r in s.select('.roma'):
r.extract()
print(s.get_text(strip=True))
打印:
私の母はあまり英語が上手に話せない。
2、3ページの英語を訳すのに2時間以上もかかりました。
こんなに上手に英語で手紙を書けるのにどうして話せないの?
英語のコミュニティでお名前とコメントを拝見し、プロフィールを拝読しました。
誰か英語を話す人はいますか。
「未来形」というのは存在しない、ということは受験英語でも一般的になりつつあります。
「順路→」といったかんじの看板を設置したいと思うんですけど、これを英語で作るとどうなるでしょうか?
この表現は日本語にはない英語の比喩表現として、私は大変気に入っています。
英語を学習する上で不可欠な、不規則動詞の活用。
中学生が英語を学ぶ際の最難関の一つが関係代名詞です。
TOEICの学習に限らず、英語を学ぶのであれば英和辞典は必携の書の一つでしょう。
アフィ狙いの釣り記事ですね。英語関係のコミュのあちこちにマルチポストしています。
まるでそれが正しい英語の証左かのように。
「まがりなりにも通じている」ということと「正しい英語を使っている」ということには雲泥の差があります。
上級者が英語力(特に読解力)をつけたければ、語彙を増やすのが王道ですね。
その当時、どこの公立の学校にもネイティブの英語の先生などいませんでした。
彼女は兄に勝るとも劣らぬくらい英語が上手だ。
彼女は英語を話すのが得意で、兄に勝るとも劣らぬくらいだ。
日本では、英語から日本語(英日)、日本語から英語(日英)への翻訳が多く、日西、西日の実需があまりありません。
英語には8つの主な品詞があります:名詞、動詞、形容詞、副詞、代名詞、前置詞、接続詞そして感嘆詞。
ちなみに私は英語がからきし駄目なんです。
話をすることで自分を曝け出すことを恐れず、英語で他人としゃべるあらゆる機会をとらえなさい。そうすればじきに形式張らない会話の場面で気楽になれるであろう。
鈴木先生は私たちに英語を教えてくれる。
例えば、君は英語が好きですか。
良い英語と、悪い英語はどのようにして区別できますか。
