
我是这方面的初学者,
我有一个分类问题,我的数据如下所示:
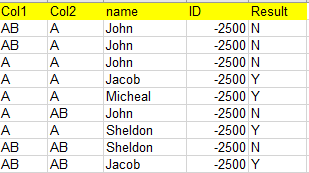
结果列是因变量。没有一个数据是有序的。(名称列有36个不同的名称。)
由于这是分类数据,我尝试了onehotcodeding,得到了ValueError:模型的特征数量必须与输入匹配
我理解并指出这一点:所以问题,它得到了修复。
还有另一个站点:Medium通过使用Pandasfactorize函数来解决这个ValueError。
我的问题是:
我的代码如下:
训练
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
dataset = pd.read_csv("model_data.csv")
dataset['Col1'] = pd.factorize(dataset['Col1'])[0]
dataset['Col2'] = pd.factorize(dataset['Col2'])[0]
dataset['name'] = pd.factorize(dataset['name'])[0]
dataset['ID'] = pd.factorize(dataset['ID'])[0]
X = dataset.iloc[:, 0:-1].values
y = dataset.iloc[:, -1].values
# Encoding
# Encoding categorical data
# Encoding the Independent Variable
from sklearn.compose import make_column_transformer
from sklearn.preprocessing import OneHotEncoder
ct = make_column_transformer((OneHotEncoder(sparse='False'), [0,1,2,3]), remainder = 'passthrough')
X = ct.fit_transform(X)
# Encoding the Dependent Variable
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
print(y)
#
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators = 5, criterion = 'entropy', max_depth = 5, random_state = 0)
classifier.fit(X_train, y_train)
# Predicting the Test set results
y_pred = classifier.predict(X_test)
测试
test_data_set = pd.read_csv("test_data.csv")
test_data_set['Col1'] = pd.factorize(test_data_set['Col1'])[0]
test_data_set['Col2'] = pd.factorize(test_data_set['Col2'])[0]
test_data_set['name'] = pd.factorize(test_data_set['name'])[0]
test_data_set['ID'] = pd.factorize(test_data_set['ID'])[0]
X_test_data = test_data_set.iloc[:, 0:-1].values
y_test_data = test_data_set.iloc[:, -1].values
y_test_data = le.transform(y_test_data)
classifier.fit(X_test_data, y_test_data) #fixes ValueError
y_test_pred = classifier.predict(X_test_data)
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test_data, y_test_pred)
print(cm)
print(accuracy_score(y_test_data, y_test_pred))
编辑:
混淆矩阵
[[113 0]
[ 0 30]]
我不确定我有大约2000行,但我的TP和TN加起来只有143个计数。
下面是如何对数据使用OneHotEncoding执行二进制分类的示例。
首先对所有具有特性的列使用一个热编码,然后将“结果”列中的Y/N类分解为1/0视图。
dataset = pd.read_csv("model_data.csv")
dataset = pd.get_dummies(dataset , columns=['Col1', 'Col2', 'name', 'ID'])
dataset.Result = pd.factorize(dataset.Result)[0]
您应该得到如下所示的结果,您可以将其用于培训/测试步骤。
初始数据帧:
Col1 Col2 name ID Result
0 AB A John -2500 N
1 AB A John -2500 N
2 A A John -2500 N
3 A A Jacob -2500 Y
4 A A Micheal -2500 Y
5 A AB John -2500 N
6 A A Sheldon -2500 Y
7 AB AB Sheldon -2500 N
8 AB AB Jacob -2500 Y
结果数据帧:
Result Col1_A Col1_AB Col2_A Col2_AB name_Jacob name_John name_Micheal name_Sheldon ID_-2500
0 0 0 1 1 0 0 1 0 0 1
1 0 0 1 1 0 0 1 0 0 1
2 0 1 0 1 0 0 1 0 0 1
3 1 1 0 1 0 1 0 0 0 1
4 1 1 0 1 0 0 0 1 0 1
5 0 1 0 0 1 0 1 0 0 1
6 1 1 0 1 0 0 0 0 1 1
7 0 0 1 0 1 0 0 0 1 1
8 1 0 1 0 1 1 0 0 0 1
希望对你有帮助。
您可以使用pd。get_dummies()方法,它通常非常可靠。这本指南应该让你开始学习。干杯
